子計畫3:系統晶片(SOC)技術研發System-on-Chip Technology
一、摘要
系統晶片將不同電子原件集中到單一晶片藉以建構完整系統。優點包括高效能、低空間需求、低記憶體需求、高系統穩定度及低成本。應用包括多媒體、資訊娛樂系統(iPod)無線設備(手機及WiFi設備)本計畫包括電子硬體設計及省電系統軟體設計。前者包括線路收發系統晶片、寬頻無線通訊系統晶片、具彈性之電子電路系統。後者包括省電即時工作排程、可應用於多核心處理器之省電即時作業系統、系統晶片效能偵測及最佳化之工具、系統晶片合成及分析工具。
前瞻系統晶片硬體設計
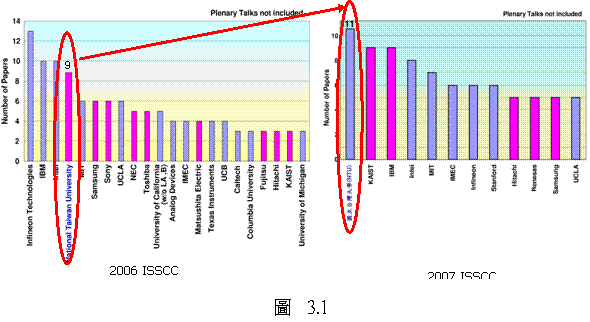
過去三年來,台灣大學於ISSCC所發表的論文數高居全球所有大學的第一名。2007年更超越IBM、Intel、TI等公司,成為世界上所有研究單位發表ISSCC論文最多者。同年亦獲得2007 ISSCC Beatrice Winner Award,這是歷史上台灣首度獲得此項大獎。面對來自全球各機構的激烈競爭,為維持台大SOC團隊的領先地位,本校優勢重點領域拔尖計畫的研究經費之持續挹注乃不可或缺。本SOC子計畫已鎖定以下三個極具挑戰性的研究主題作為努力的目標:
(1)
10-Gbps transceiver SOC for twisted pair
(2)
Broadband 60-GHz wireless communication SOC
(3) TFT
circuit/system for flexible electronics
前瞻系統晶片軟體設計
本研究主軸是以效能工程來改善系統服務品質的各種關鍵技術。目標是開發作業系統中的關鍵元件來支援有即時與省電節能需求的應用系統,包括系統或應用程式效能瓶頸的相關技術,多核心硬體平台即時效能與省電節能,動態電壓調整工作排程、漏電即時工作管理、動態功率管理、優先權反轉與省電節能的工作同步。
二、重大突破
論文方面
團體成就方面: 在過去三年之 ISSCC( 又稱 ” 晶片奧林匹克競賽 ”) 中,台灣大學表現優異,所發表的論文數,高居全世界所有大學中的第一名。詳言之, 2005 年、 2006 年,臺大的 ISSCC 論文數已領先世界其他大學; 2007 年更進一步成為世界所有研究單位(包含所有大學及公司如英飛凌、 IBM 、英特爾及德州儀器等)之最。
個人成就方面: 台大 SoC 團隊之 李致毅 教授,創下全世界最高的鎖相回路操作頻率紀錄,並因而獲致 2007 年 ISSCC Beatrice Winner Award ,此為台灣第一次在 ISSCC 所 獲的最佳論文獎 .

技術方面
1 、快閃記憶體儲存系統 (Flash-Memory Storage Systems)
有鑑於快閃記憶體 (flash memory) 在可靠性提升 (reliability enhancement) 方面有很強烈的需求。我們的研究考量在有限的記憶體空間與不大量改變設計架構 ( 例如 FTL and NFTL) 之情況下,提升快閃記憶體之耐用性 (endurance) 。我們提出了一個只需有限記憶體空間與能迅速實作之靜態耗損均衡機制 (static wear leveling mechanism) 。透過一連串的實驗,證實我們的機制可能大大提升 FTL 與 NFTL 之耐用性。許多例子中,快閃記憶體的壽命能夠變為原來的兩倍。這篇論文已於
2007 年被最好的設計自動化會議接受
: ACM/IEEE Design Automation Conference (DAC) 。本論文並獲提名大會之最佳論文獎。
2 、 數位微流體試生物晶片之擺置
我們提出了一個目前最先進的數位微流體晶片擺置的演算法。我們是第一個將時間平面規劃和時序樹等方法應用於擺置的問題上。跟之前的方法相比較,我們的方法可以在最短的時間之內得到最好的結果。
3 、 以硬體設計為導向的低密度奇偶校驗編碼設計與高速階層類迴旋低密度奇偶校驗編碼解碼器設計
在這個作品中我們提出一個易於硬體實做的結構化且具有低錯誤下界的低密度奇偶校驗編碼。相較於類迴旋編碼,提出的編碼在較長的編碼長度下並無明顯的錯誤下界。利用修改的 PEG 演算法來建立階層類迴旋低密度奇偶校驗編碼。藉由加入易於硬體實做的雙階層與第二階層子矩陣限制,編碼增益得以提升超越類迴旋編碼。以類迴旋編碼為基礎的解碼器結構可以簡單的套用於階層類迴旋解碼器並可以提升編碼增益與產出量。其中亦提出利用重疊訊息傳遞排程演算法設計高產出量的低密度奇偶校編碼。在設計中使用正規階層類迴旋編碼得以在長編碼長度下提供良好的編碼增益。利用雙階層正規階層式低密度奇偶校驗編矩陣結構平行解碼化列運算與解碼行運算。我們設計的排程演算法重新排列不同迴圈的解碼運算以避免記憶體存取衝突。相對於無排程演算法的管線式解碼器,記憶體需求減少一半。一個
(12288, 6144) 低密度奇偶校驗編碼解碼器 FPGA 實做,產出量為 781M bps 。
4 、 使用快速收斂階層訊息傳遞演算法之低密度奇偶校驗編碼解碼器應用導向特殊整合電路實作
在此著作中,提出一個使用快速收斂階層解碼演算法之 (12288, 6144) 低密度奇偶校驗編碼解碼器。標準訊息傳遞演算法是序列的,所以已更新的資訊可以在反覆解碼過程中較早被利用。反覆次數可以被減少一半而不降低編碼增益。這個設計使用兩階層類迴旋低密度奇偶校驗編碼,當編碼長度較長時,提供良好的編碼增益以及較低的錯誤下界。第二層 32x32 的次矩陣的可以平行解碼運算來增加輸出率。處理單位管線化可以增加輸出率而無複雜的排班演算法。低複雜度應用導向特殊整合電路實作可以達到
400M bps 的資訊輸出。
5 、 MFASE: 亞洲第一個 Electronic System Level (ESL) 設計工具
效能與可靠性是評估多功能單晶片系統最重要的兩種度量。 MFASE 工具在系統層提供設計建議,並在系統層與交易層驗證設計。設計人員可以在設計的早期階段避免設計錯誤以減少花費並縮短上市時間。在我們的測試案例中, MFASE 工具能節省 60% 的花費,並把設計時間從數天減少到數小時。我們這個研究團隊已被邀請到兩個國際會議發表,並在一本書上刊登本設計。
6 、 JPEG-LS 編碼技術在 ARM9 平台之效能最佳化的方法 (2) 與廣達研究院在儲存伺服器效能改良及系統架構設計之產學研究合作案
第一項是我們贏得競賽的作品 : JPEG-LS 是一個有名的非損失性 (loss-less) 的 JPEG 影像編碼技 術, 我們對於這個開放原始碼程式效能的改良和程式碼的縮 短,使得 JPEG-LS 能夠更為有效應用在的在低功率 / 低成本的嵌入式系統 上。針對 ARM9 平台,我們提出一套有系統的效能調校方法,成功地將其效能增進為原先的 33 倍之多,同時也把程式碼縮 短成為原有的 1/ 7 。 這個成果,在美國 ARM 公司與國家晶片系統設計中心 (CIC) 所合辦的 2006 年度
ARM Code-O-Rama Design Contest 之中奪得第一名的榮
譽。
第二項是我們與廣達研究院的產學研究合作案: 儲存伺服器被許多人認為是電腦產業的明日之 星,而 在這個研究之中,我們要在一個非常複雜的商用儲存伺服器上進行效能分析以及改進其架構。由於這個商用儲存伺服器上的原始程式碼超過 10,000,000 行,即使是資深的程式設計師也無法找出效能問題的所在。因此我們與廣達合作,利用這個機會把商用儲存伺服器的技術帶入學校,進行深入的分析與研究,以我們所開發出來的效能分析工具發現瓶頸所在。因 此,我們首先根據分析,經由程式碼的最佳化將這個產品的效能增進了
10 % ,更近一步, 我們在現有系統架構中加入快取記憶體的快速搜尋機制 , 使得常用的檔案的存取速度提升六倍之多。由於系統的複雜度,大幅提高這個研究的難度,因而我們研究的重點也在於找尋比現有的方法更實用,更有效 率的自動化 效能分析技 術。 .
三、研究成果
除了上述之重大突破外, 台大 SOC 團隊亦獲得很多相當傑出之研究成果(臚列於下一節重要論文),以下僅擇其要者說明。
陳良基教授的專長領域是數位訊號處理與視訊 IC 設計, 96 年主要研究成果包括發表於國際最著名的 ISSCC2006 的 Motion-JPEG2000 編解碼器,低功率 MPEG-4 編碼器,以及發表於 2007 年 Symposium on VLSI Circuits 的功率感知 H.264/AVC 編碼器,以及 Graphics 用的處理器核心。 陳 教授實驗室研發的 video IC 已經技轉給十多家影像視訊產品的廠商,扶植本土產業,使廠商不必受制於核心技術掌握日商手中。這些影像壓縮晶片廣泛備應用於數位相機,攝影機,視訊監控,多媒體電話等產品。陳教授每年的技轉金超過千萬,是學界中的佼佼者,故而今年更獲得「大學產業貢獻獎」的肯定。
( 如 圖 3.3)

「台大 - 聯發科技無線整合系統實驗室」自 2001 年接受聯發科技贊助成立以來,以開發前瞻性技術計畫為主,發展主導性產品為輔,致力於提升國內 IC 研發產業水準。初期以加速台灣無線射頻領域發展為主要努力方向,與國內工業界合作,成功地奠定了產學合作新模式的基礎;迄今 6 年期間,實驗室成果豐碩,創下多項研究殊榮, 2007 年在全球 IC 設計學術發表指標的國際固態電路會議 (ISSCC) 上,更以 10 篇論文發表而居全世界實驗室 翹楚 ,讓台灣產學界藉國際性研討會登上世界舞台,提升台灣於國際學術及工業界的能見度。今年更獲得『大學產學貢獻團體獎』的榮譽。
( 如 圖 3.4)

有了超大型積體電路設計的先進技術,許多現代的處理器都能在不同的供應電壓下運作。各種技術如 Intel 的 SpeedStep? 與 AMD 的 PowerNOW? 都提供了動態電壓調整 (dynamic voltage scaling , DVS) 給膝上型電腦延長電池的使用壽命。不同的供應電壓在一個可動態電壓調整的處理器上可導致不同的執行速度。在嵌入式系統上著名的處理器例子有 Intel 的 Strong ARM SA1100 和 XScale 。有動態電壓調整的處理器上的電源消耗是處理器速度的一個遞增凸面函數。許多電腦系統都用
DVS 也就是降低供應電壓來降低能源消耗。供應電壓越低處理,處理器速度就越低,動態電壓調整的能源消耗也越低。不過,由於漏電電流產生的能源消耗卻提高,因為處理器低速運行,會延長工作執行時間。這樣的問題在現代嵌入式系統採用多核單晶片技術之後更行重要。
我們的研究目標不僅是在學術研究上,也著重在嵌入式軟體的最新技術開發。我們會針對漏電問題與通曉溫度探究在單一處理器與多重處理器上有效率能耗的即時工作排程。我們也會考慮在較複雜系統架構的處理器與裝置上整合性的排程與 profiling 議題。在系統元件設計上,我們會延伸在快閃記憶體儲存系統上的成果成為針對嵌入式單晶片軟體的整合性設計,並建構一以聲音為主的行動系統來做技術評估。值得注意的是快閃記憶體已經成為許多混合式嵌入式單晶片裝置上的重要元件,如著名的
Intel Robson 產品,而且以聲音為主的行動系統本身就有即時效能與有效率能耗的需求。因為嵌入式軟體是單晶片系統設計上的關鍵元件,我們的研究將會在系統設計上讓台灣的
IC 工業更具競爭力。
我們的目標是在嵌入式單晶片軟體中探索幾個重要並有高挑戰性的議題,尤其是在動態電壓調整上的即時工作排程。我們也會在有效率能耗與效能導向設計的相關主題上密切合作,並開發包括系統軟體設計、系統架構、與硬體平台各種層面上在最小化能耗與滿足時間限制之間的折衝。我們也會選擇一些平台進行量測,來驗證我們的模型、架構、與問題定義。我們必須指出事實上即時工作排程是一種效能工程技術,可以作為許多系統與應用設計中最佳化問題的基礎技術。此外,最小化能耗與滿足時間限制之間的折衝其實來自於滿足時間限制通常會導致較多的能源消耗,因為我們通常想要在時限之內完成工作。
四、重要論文
International Solid-State Circuits Conference (ISSCC):
˙ K. H. Chen and T. D. Chiueh, "A 1.8V 165mW Discrete Wavelet Multitone Baseband Receiver for Cognitive Radio Applications," accepted by IEEE ISSCC, San Francisco, CA, February 2007.
感知無線電的目標是希望將無線電系統賦予如同人類的大腦一般能力,可以去感知外界的變化,並針對目前身處的環境作出正確的判斷並調整其系統參數以儘可能利用可使用的頻譜資源。本研究係國際間首度成功以小波( wavelet )調變技術於無線通訊之應用。本研究成果可以充分利用 GSM 系統中未使用之頻譜,進而提供可提供高達 153.6 M bps 速率的家用無線資料傳輸。此研究所設計之晶片亦也已在世界知名之 2007 年國際固態電路會議 (ISSCC) 中發表。
˙ Chihun Lee and Shen-Iuan Liu , "A 58-to-60.4GHz frequency synthesizer in 90nm CMOS", International Solid-State Circuits Conference (ISSCC) 2007, pp.196-197, Feb. 2007
這篇論文呈現一個工作於 58-60.4 十億赫茲的頻率合成器,使用 90 奈米互補式金氧半導體製程來製造。使用分布式電感電容壓控振盪器以及電流再使用式除法器,在包含緩衝器的情況下,這顆晶片使用 1.2 伏特的供應電壓並消耗 80 毫瓦的功率。
˙ Lan-Chou Cho, Chihun Lee and Shen-Iuan Liu , "A 33.6-to-33.8Gb/s burst-mode CDR in 90nm CMOS", International Solid-State Circuits Conference (ISSCC) 2007, pp.48-49, Feb. 2007
這篇論文呈現一個工作於每秒 33.6-33.8 十億位元的突發式時脈資料回復電路,使用 90 奈米互補式金氧半導體製程來製造。使用電感電容閘式壓控振盪器、相位選擇電路、輸入阻抗匹配電路以及寬頻緩衝器,在包含緩衝器的情況下,這顆晶片使用 1.2 伏特的供應電壓並消耗 73 毫瓦的功率。
˙ Chih-Fan Liao and Shen-Iuan Liu , "A 40Gb/s Transimpedance-AGC amplifier with 19dB DR in 90nm CMOS", International Solid-State Circuits Conference (ISSCC) 2007, pp.54-55, Feb. 2007
本論文使用 90nm CMOS 製程實現了一個 40G b/s 轉導放大器。利用回授的技巧使得傳統放大器所需的偏壓電流降低,同時可維持低輸入阻抗的特性 ; 同時提出了一個三次諧振網路的方法,可增加放大器的頻寬。此電路的振幅為 260m V PP ,輸入動態範圍為 19dB ,輸出擾動小於 l0ps pp ,功率消耗為 75m W 。
˙ Chi-Nan Chuang and Shen-Iuan Liu, "A 40GHz DLL-based clock generator in 90nm CMOS technology", International Solid-State Circuits Conference (ISSCC) 2007, pp.178-179, Feb. 2007
本論文介紹一個利用 90nm CMOS 製程所實現的 2~ 5G Hz 多相位多週期鎖定的延遲鎖定迴路,利用啟動電路加上除法器的方法,可以使得延遲鎖定迴路達到更高的工作頻率,降低充電泵以及相位比較器的速度限制,並且可以防止延遲鎖定迴路發生錯誤鎖定以及諧波鎖定的情況,當此延遲鎖定迴路工作在 5G Hz 時其實際量測的方均根以及峰對峰抖動分別為 0.874ps 以及 7.56ps ,藉由此種方法實現了一個 40G Hz 的時脈產生器,其晶片面積為 0.374x 0.326 m m2 且輸入電壓在 1V
時所消耗的功率為 45m W 。
˙ Jri Lee, "A 75GHz PLL in 90 nm CMOS," Digest of International Solid-State Circuits Conference, pp. 432-433, Feb. 2007.
藉由電路模擬和晶片實驗證明,此論文提出一利用 90 奈米製程製作之 75-GHz 鎖相迴路。電路採用了四分之三波長的技巧來分散雜散電容,提高震盪器之震盪頻率,此外,也提出一個基於單邊頻帶混頻器之相位頻率偵測器,能有效壓抑參考頻率的擾動。此鎖相迴路有 320 M Hz 的操作範圍,參考頻率邊帶低於 -72 dBc , 功率消耗在 1.45 V 下為 88 mW 。
˙ Jri Lee and M. Liu, "A 20-Gb/s Burst-Mode CDR in 90-nm CMOS," Digest of International Solid-State Circuits Conference, pp. 46-47, Feb. 2007.
此 20-Gb/s 時脈資料回復電路採用注入鎖定的技巧,以低消耗功率即可達成高速操作的目的。串接兩級的注入式震盪器,能有效減低因資料注入所造成在回復時脈上的擾動,配合一頻率追蹤偵測機制,能有效增加頻率操作範圍,避免製程溫度變異的影響。本電路利用 90 奈米製程製作,在連續或突發式操作下,位元錯誤率皆可低於 10 ? 9 ,功率消耗在 1.5 V 下為 175 mW 。
˙ Jri Lee and Huaide Wang, "A 20-Gb/s Broadband Transmitter with Auto-Configuration Technique," Digest of International Solid-State Circuits Conference, pp. 444-445, Feb. 2007.
此論文提出一運用於電路版背版通訊的資料傳送機,有別其他設計,本電路不需要電路版上額外的通道,即可在開機時隨通道長度自我調整信號補償大小。此電路包含了一組採用可調式預先增強器的傳送機,以及相對應的接收機。實驗結果證明此電路可在 20 公分 的電路版上傳送資料,傳輸速度達 20 G b/s 時 位元錯誤率仍可低於 10 ? 12 。
IEEE Journal of Solid-State Circuits (JSSC):
˙ Hsiao-Chin Chen, Tao Wang, and Shey-Shi Lu, “A 5-6 GHz 1-V CMOS Direct-Conversion Receiver with an Integrated Quadrature Coupler”, IEEE Journal of Solid-State Circuits, SC-42, pp. 1963-1975, Nov. 2007.
本論文提出一種新的直接降頻接收機結構,主要以九十度耦合器及次諧波混波器來避掉因本地振盪器自混波所造成的直流電壓偏移之問題。本接收機係以 0.18 um CMOS 技術製成,在 5 -6 G Hz 頻率範圍下,電壓增益為 26.2 dB 而雜音指數為 5.2 dB 。功率消耗為 45.5 mW ,操作電壓為 1V 。以輸入端為參考點之直流電壓偏移被壓抑至 -110.7 dBm 以下。
˙ Rong-Jyi Yang and Shen-Iuan Liu , "A 2.5GHz all-digital delay-locked loop in 0.13μm CMOS technology", IEEE Journal of Solid-State Circuits, SC-42, pp. 2338-2347, Nov. 2007.
本論文提出一個利用 0.13um CMOS 製程所製作的 2.5G Hz, 30m W, 0.03m m2 全數位延遲鎖定迴路,利用三種狀態的數位相位偵測器抑制了相位顫抖的現象,並且利用計數器來控制數位延遲鎖定迴路已達到降低峰對峰值抖動的效果,晶格式的延遲單元具有小的延遲以及固定兩個 NAND 閘的延遲,改良式漸進式紀錄控制鎖定方法降低了鎖定時間,並且可以抵抗由於製程、溫度以及負載變化所造成的影響,此全數位延遲鎖定迴路僅需 24 個時脈週期即可鎖定,並且具有閉迴路的特性,當晶片工作在
2.5G Hz 時輸出時脈的峰對峰抖動僅有
14ps.
˙ Chih-Fan Liao and Shen-Iuan Liu , "A broadband noise-canceling CMOS LNA for 3.1-10.6-GHz UWB receivers", IEEE Journal of Solid-State Circuits, SC-42, pp. 329-339, Feb. 2007.
本論文提出一個寬範圍全數位延遲鎖定迴路,可以達到低抖動、低功率以及具有抵抗電壓變動的特性,利用可變動漸進式紀錄控制演算法以達到防止在寬頻操作時的諧波鎖定,並且可以達到快速鎖定以及閉迴路鎖定的特性,藉由平衡式邊緣接合器此全數位延遲鎖相定路可以達到時脈同步並且在輸入時脈有效週期變動從 20% 變動到 80% 時依然可以產生具有 50% 有效週期輸出時脈,利用 0.18um CMOS 製程完成此全數位鎖定迴路晶片,當其輸入時脈在 40~ 550M Hz 時並且鎖定在一個輸入週期內時,此延遲鎖相迴路將不會有諧波鎖定的問題,當迴路工作在
550M Hz 輸入電壓 1.8V 時其功率消耗為 12.6m W ,輸出訊號的方均根以及峰對峰抖動分別為 1.5ps 和 12ps 。
˙ Chih-Fan Liao and Shen-Iuan Liu , "A broadband noise-canceling CMOS LNA for 3.1-10.6-GHz UWB receivers", IEEE Journal of Solid-State Circuits, SC-42, pp. 329-339, Feb. 2007.
本論文實現了一個使用寬頻雜訊消除技巧的 3.1 -10.6G Hz 低雜訊放大器。藉由提出的電路設計方法,匹配元件所產生的雜訊在超寬頻系統之中會被被抑制,而用來作為雜訊消除的元件本身所產生的雜訊也會被降低。此電路的增益為 9.7dB ,頻寬為 1.2– 11.9G Hz ,雜訊指數為 4.5–5.1dB ,功率消耗為 20m W 。
˙ Lan-Chou Cho, Chihun Lee, and Shen-Iuan Liu , "A 1.2V 37-38.5GHz 8-phase clock generator in 0.13um CMOS technology", IEEE Journal of Solid-State Circuits, SC-42, pp.1261-1270, June 2007.
這篇論文呈現一個工作於 37-38.5 十億赫茲的時脈產生器。使用八相位電感電容壓控振盪器來產生多相位輸出,分離負載式除法器被使用來增加輸入頻率的範圍,相位偵測器可改善靜態相位誤差,並提升增益,此時脈產生器使用 0.13 微米互補式金氧半導體製程來製造。
˙ T.-H. Lin and Y.-J. Lai, “An Agile VCO Frequency Calibration Technique for a 10-GHz CMOS PLL,” IEEE J. Solid-State Circuits, vol. 42, pp. 340-349, Feb. 2007.
本篇研究著作之創新與貢獻,在於提出了一個全新的壓控振盪器快速選頻的電路架構。此選頻電路可大幅降低振盪器在頻率校正上所耗的時間,此方法比現有的其他方式快速甚多,有助於大幅降低通訊系統的時間損耗,進而提升通訊系統的效能。
IEEE Transactions on Circuits and Systems for Video Technology:
˙ Chang, Y.W., Cheng, C.C., Chen, C.C., Fang, H.C., and Chen, L.G., “124 MSamples/s Pixel-Pipelined Motion-JPEG 2000 Codec Without Tile Memory,” Circuits and Systems for Video Technology, IEEE Transactions on, Volume 17, Issue 4, April 2007.
一個具有每秒一億兩千四百萬個取樣點的計算能力的 JPEG 2000 編解碼器在 0.18um 製程上實現。本晶片面積佔 20.1m m2 ,工作在 1.8V 、 42M Hz ,消耗 385m W 。本晶片能以 30 張畫面 / 秒即時處理 1920x1080 解析度的高畫質影片。從過去的研究成果中,瓷磚等級的管線化排程被用在離散小波轉換及嵌入式塊狀編碼之間。對一個大小為 256x256 的瓷磚而言,若實現在晶片內,該架構需要 175 千位元組的靜態記憶體,若是存在外部的瓷磚記憶體,則需要佔去 3 億 1 千萬個位元組
/ 每秒的同步式動態記憶體頻寬。在這個設計裡,一個階級切換排程被利用來消去瓷磚記憶體,並使離散小波轉換與嵌入式塊狀編碼之間以像
層級來排程,這個排程方法消去了晶片內部的 175 千位元組的靜態記憶體及 3 億 1 千萬個位元組 / 每秒的同步式動態記憶體頻寬。這個排程的實現是利用層級切換離散小波轉換和編碼方塊切換的嵌入式塊狀編碼。這個編碼與解碼的功能被實現在單一硬體中,編碼器與解碼器的硬體共用總計減少了 40% 的晶片面積。
˙ Chen, T.C., Chen, Y.H., Tsai, S.F., Chien, S.Y., and Chen, L.G., “Fast Algorithm and Architecture Design of Low-Power Integer Motion Estimation for H.264/AVC,” Circuits and Systems for Video Technology, IEEE Transactions on, Volume 17, Issue 5, May 2007.
在整個 H.264 編碼器之中,整數像素點移動估計器耗費了 74.29% 的運算複雜度以及 77.49% 的記憶體存取,嚴然成為整個硬體架構設計最為關鍵的部份。根據我們的分析,一個最佳化的低功率整數點移動估計器必須是個平行化的架構,不但要能支援快速演算法,還必須有很有效率的資料再利用能力。這篇論文中提出了一個能支援候選區塊內部及彼此之間的資料再利用、以硬體為導向的快速演算法。基於心跳陣列以及二維樹狀加法器的架構,我們提出了一個梯狀的搜尋視窗資料安排和一個先進的搜尋流程,用以支援候選區塊彼此之間的資料再利用,以及減少潛伏時脈。根據我們的實作結果,快速演算法可節省
97% 的運算複雜度。此外,我們提出的資料再運用的硬體架構,可省去 77.6% 的記憶體存取需要。在超級省電模式下,對於一個每秒 30 張的影像,運作在 13.5M Hz 的運作頻率的硬體,我們提出的架構只需要 2.13m W 的功率消耗。
˙ Chen T.C., Tsai C.Y., Huang Y.W., and Chen, L.G., “Single Reference Frame Multiple Current Macroblocks Scheme for Multiple Reference Frame Motion Estimation in H.264/AVC,” Circuits and Systems for Video Technology, IEEE Transactions on, Volume 17, Issue 2, Feb. 2007.
由於多張參考圖框的移動估計演算法, H.264 編碼器需要極高之記憶體存取次數。傳統的多參考圖框單一現在區塊的處理程序只考慮到一個參考圖框內的資料再利用。這個方法需要的在晶片上記憶體容量以及不在晶片上的記憶體存取量,是跟參考圖框的數目成正比的。在本篇論文,我們提出了單一參考圖框多現在區塊的處理程序,妥善運用到了在不同參考圖框之間的資料再利用。首先我們在圖框層級上,對移動估計在不同參考圖框的排程重先規劃,使得一個已下載參考區域可以被不同的現在區塊所利用。之後,我們根據這樣的排程,設計了我們的兩段式模式決定。針對高解析電視的規格,相較於傳統的多參考圖框單一現在區塊的處理程序,我們提出的架構可節省
74.8% 記憶體容量以及 62.6% 的系統頻寬需要。
˙ Cheng, C.-C., Huang, C.-T., Chen, C.-Y., Lian, C.-J., and Chen, L.-G., “On-Chip Memory Optimization Scheme for VLSI Implementation of Line-Based Two-Dimentional Discrete Wavelet Transform,” Circuits and Systems for Video Technology, IEEE Transactions on, Volume 17, Issue 7, July 2007.
在條狀式架構二維離散小波轉換晶片的記憶體對整體晶片的面積大小及功率消耗扮演舉足輕重的角色。本篇論文對條狀式架構二維離散小波轉換提出了一套高效能記憶體超大規模積體電路設計之實作方式,其中包含兩個部分:字碼長度分析分法以及多重提升式架構。基於我們所提的字碼長度分析方法決定所需的記憶體字碼長度之後,我們提出了一套高效能記憶體超大規模積體電路設計之實作方式(多重提升式架構)。字碼長度分析方法可以避免係數溢位問題,實作的結果指出,本架構對影像畫質的影響只有
0.1 分貝。多重提升式架構不僅降低了至少
50% 晶片記憶體頻寬,同時也減少了 50% 的記憶體緩衝區面積。
˙ G.Y Chang, G.H Chen, and G.J Chang (2007), “(t,k)-diagnosis for matching composition networks under the MM* model, ”IEEE Transactions on Computers, vol.56,no.1,pp.73-79.
˙ Y.H. Tseng, E.H.K. Wu, and G.H. Chen (2007), “Scene-change aware dynamic bandwidth allocation for real-time VBR video transmission over IEEE 802.15.3 wireless home networks,”IEEE Transactions on Multimedia, vol.9, no.3, pp.642-654.
˙ C.Y Chiu, E.H.K. Wu, and G.H. Chen (2007), “A reliable and efficient MAC layer broadcast protocol for mobile ad hoc networks,” IEEE Transaction on Vehicular Technology, vol.56, no.4, pp.2296-2305.
˙ P.-H. Yuh, C.-L. Yang, and Y.-W. Chang, Placement of Defect-Tolerant Digital Microfluidic Biochips, to appear in ACM Journal on Emerging Technologies in Computing Systems (JETC), 2007
˙ P.-H. Yuh, C.-L. Yang, and Y.-W. Chang,Temporal Floorplanning Using the Three Dimensional Transitive Closure SubGraph, to appear in ACM Transaction on Design Automation of Electronic Systems (TODAES), 2007
˙ Huang, Y.-K., Pang, A.-C., and Hung, H.-N, "An Adaptive GTS Allocation Scheme for IEEE 802.15.4", accepted and to appear in IEEE Trans. on Parallel and Distributed Systems, 2007
|


